
Scalable analytics with Google Cloud Platform, dbt and Looker
Extracting value from data isn’t always straightforward. Even simple tasks—like combining different data sources, automating data updates, and turning raw numbers into clear insights—can quickly become messy and confusing. Valuable information gets lost, and good decisions become harder to make.
Why data pipelines matter?
Without a structured approach, data ends up fragmented and hard to understand. Teams spend more time cleaning up the mess than actually analyzing and using their data. This not only slows down decision-making but can also prevent seeing the full picture of what's going on—missing out on opportunities to improve.
Use a structured and automated approach
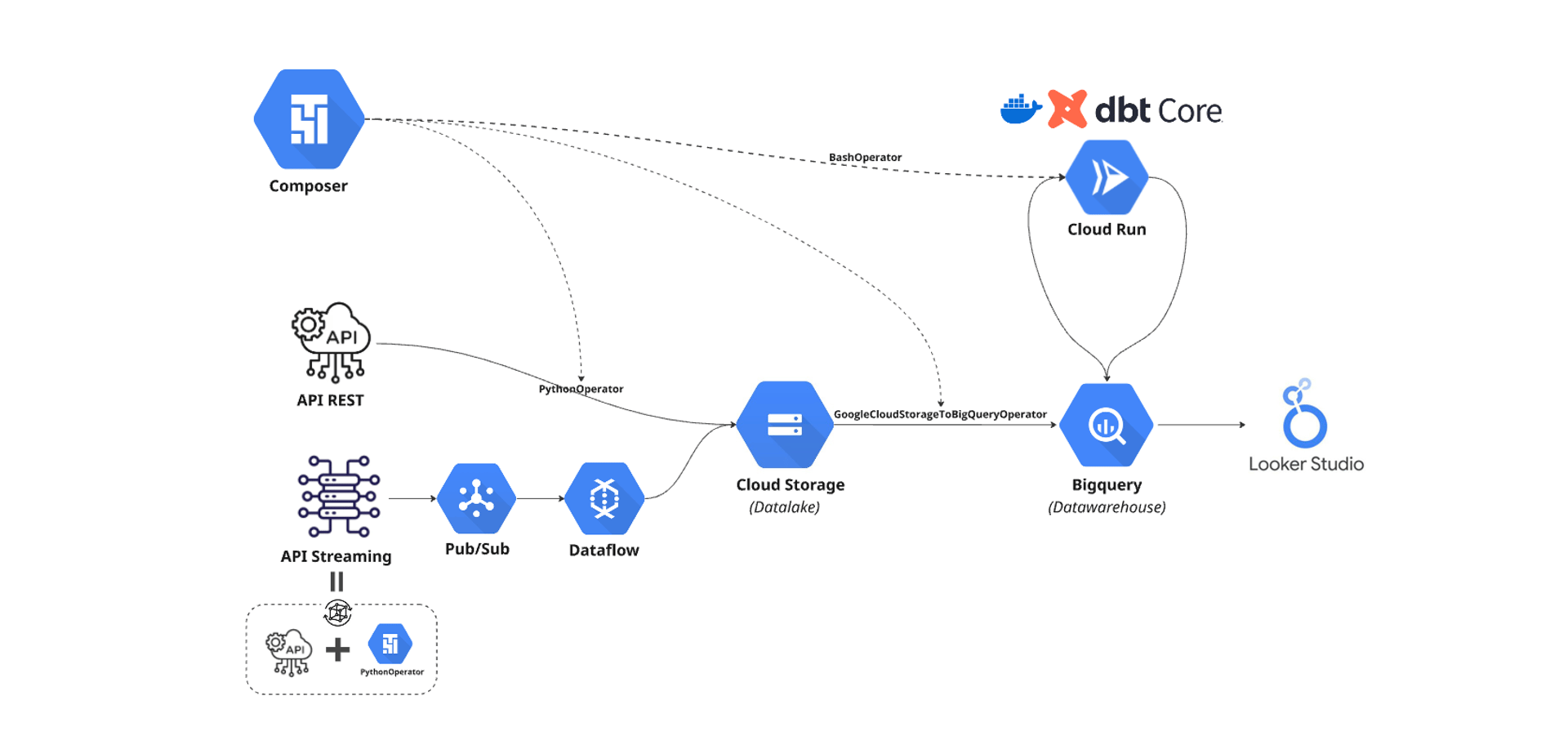
A fully automated and organized data pipeline using Google Cloud Platform and dbt solves these challenges. By clearly structuring the way data flows—whether it's coming in real-time or in batches—it becomes simple to transform raw data into valuable insights. Data becomes easy to handle, understand, and visualize, helping teams quickly discover patterns, trends, and opportunities.
How It Works
Real-world Data Simulation: Realistic batch and streaming data are simulated through automated processes, giving practical and relevant scenarios.
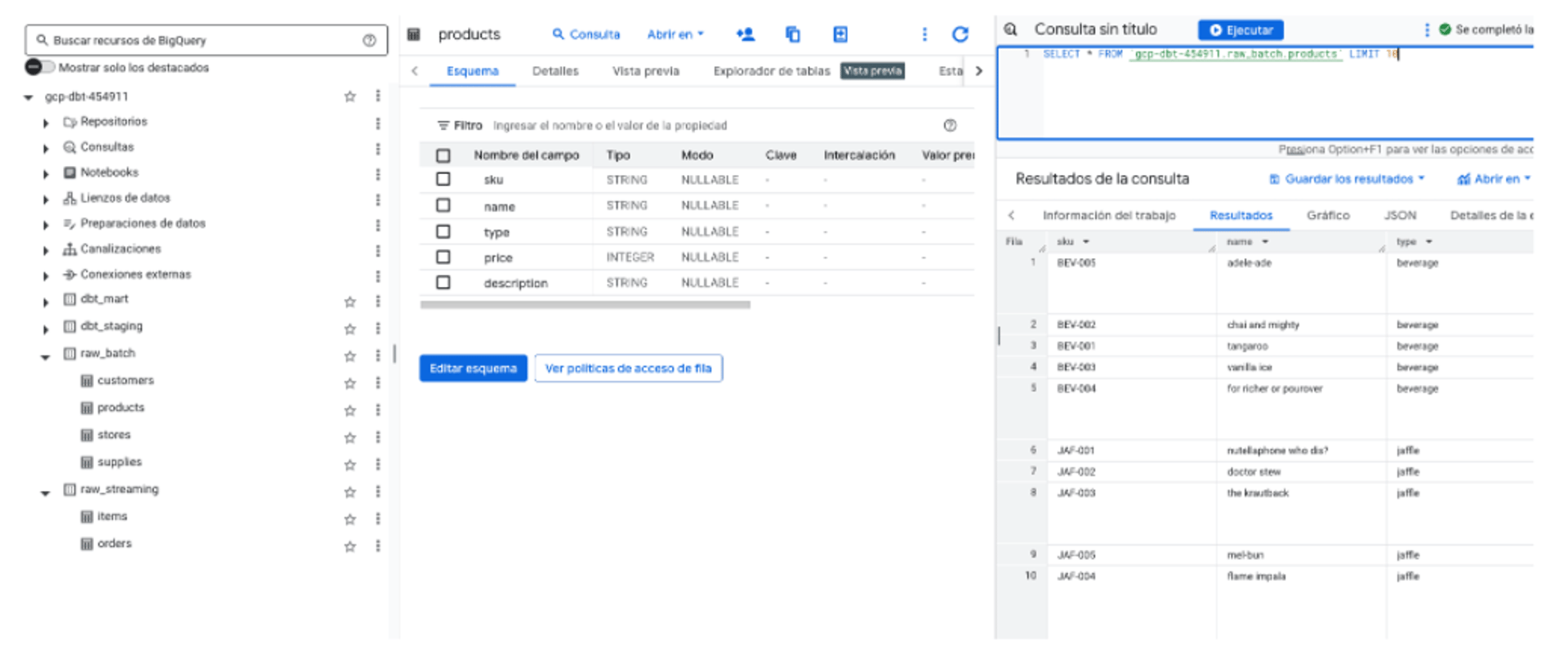
Organized Data Storage: Raw data is automatically ingested through Cloud Composer (Airflow) jobs for batch data and Pub/Sub + Dataflow for streaming data, and neatly organized into Cloud Storage, creating a reliable datalake.
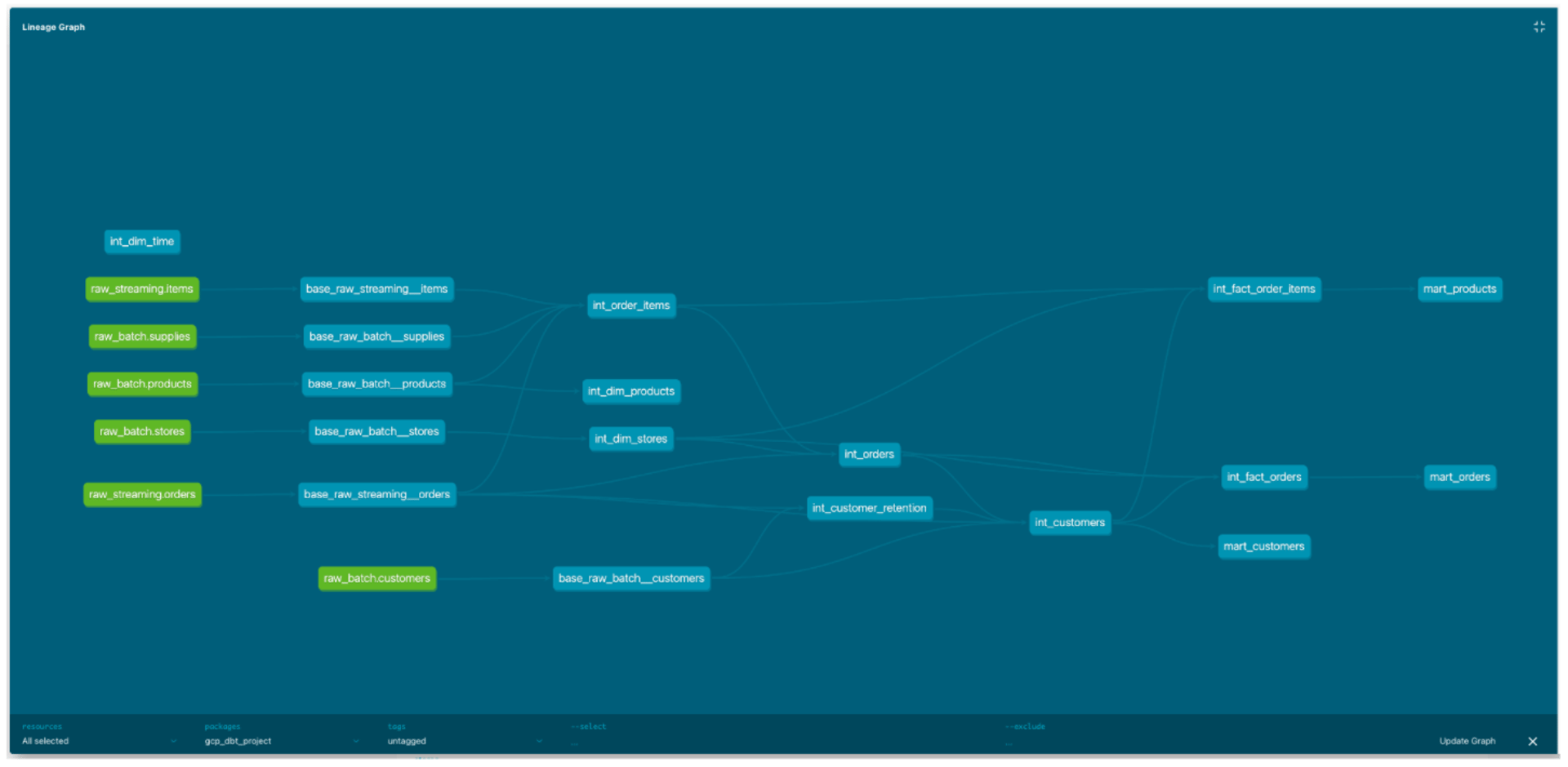
Efficient Data Transformations: dbt processes and cleans raw data directly on Cloud Run, preparing it clearly for analysis in BigQuery Datawarehouse.
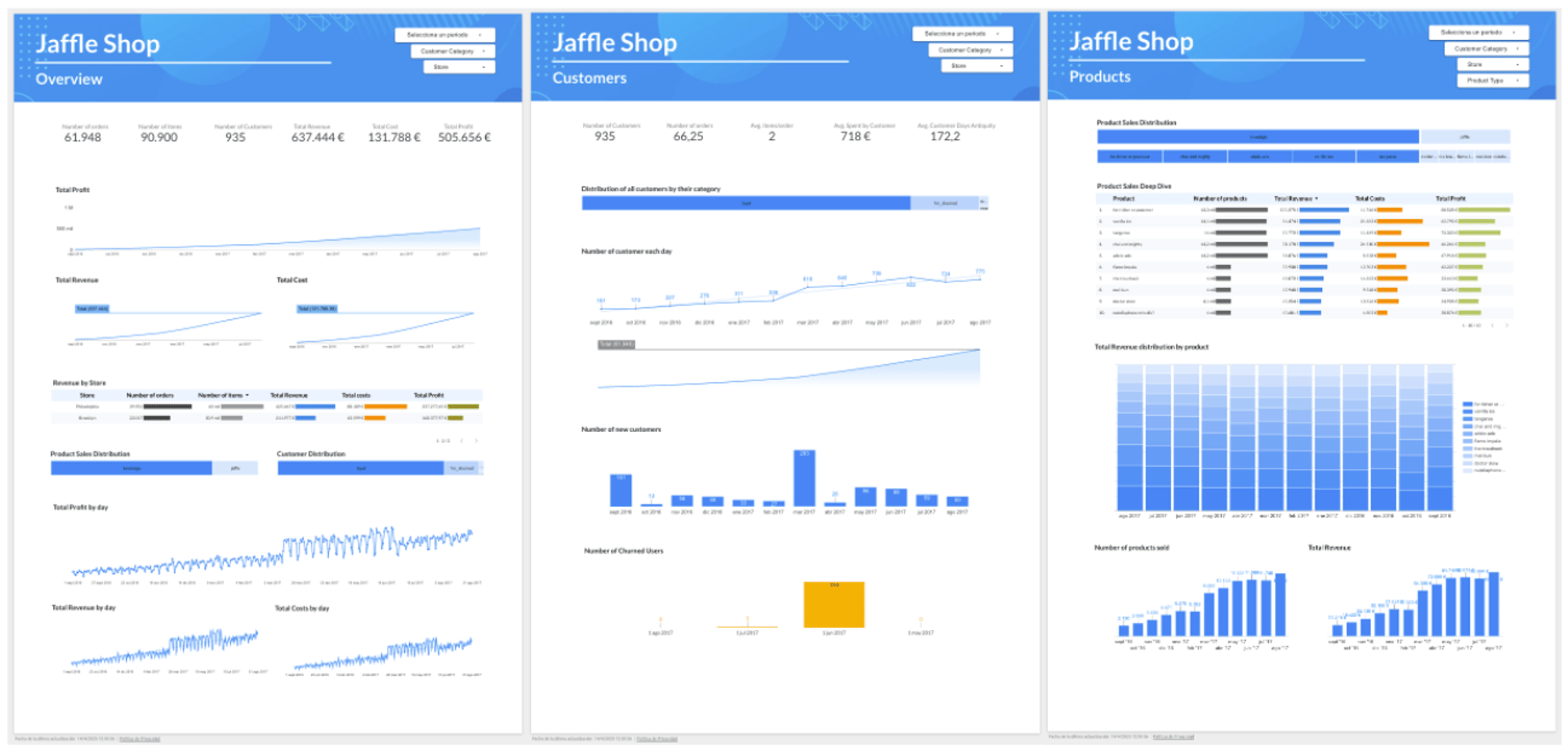
Clear Visualization: Cleaned data is visualized with Looker Studio dashboards, making metrics easy to interpret, and insights quick to grasp.
Automated Orchestration: Airflow running on Cloud Composer coordinates the entire flow, managing data ingestion, transformations, and monitoring pipeline health—keeping the entire system reliable and fully automated.